

What Happens to Detections When Agents Do the Work
The mindset shift from alerting for humans to alerting for AI agents.

Welcome to Detection at Scale, a weekly newsletter on AI-native security operations. I’m Jack, Founder & CEO at Panther. If you find this valuable, please share it!
Every detection you’ve ever written was, at its core, a message to a human. The alert title, the severity label, the description, and the runbook — all of it was carefully designed to transfer situational awareness to an analyst as fast as possible. The assumption baked into that design was that a person would be on the receiving end: someone who would read the alert, follow a set of deterministic steps (check the asset inventory, look up the user’s recent activity, consult the runbook), and decide what to do next. That workflow, whether executed manually or partially automated through SOAR playbooks, was fundamentally built around human cognition as the reasoning engine. That assumption is now changing.
AI agents are increasingly handling the first layer of alert triage and investigation in modern SOCs. When an agent is the first reader of your detection, almost everything about what makes that detection good changes. The fields that matter, how severity gets used, what a runbook is actually for, and what noise even means all shift. And critically, the detection itself evolves: rather than pure rule logic designed to fire a signal at a human, detections combine rule logic with natural language prompts that communicate the threat model, the criteria for risky versus benign, and the investigative intent behind the rule. You’re not just writing logic anymore; you’re providing guidance for a sophisticated reasoning system.
The human role in this model doesn’t disappear; it becomes more strategic. The questions that require human judgment shift from “is this alert legitimate?” to “how would we judge this particular type of alert as risky?” Coverage decisions, compliance requirements, and threat modeling for your specific environment are areas where human expertise sets the direction that agents then execute against.
In this post, we’ll review the evolution from human-led to AI-led alerting in the SOC: what the old world looked like, what concrete changes the new one brings, and what practical steps teams can take to build detections for an agentic SOC.
The Old World: Detections Designed for Human Throughput
To understand what changes, let’s review how the current detection lifecycle works.
A detection engineer writes a rule: some combination of log conditions, thresholds, and field matching that fires when a specific pattern appears in the data. The rule generates an alert with a title, severity level, description, and, ideally, a runbook outlining next steps. That alert lands in a queue (a SIEM console, a ticketing system, a Slack channel) and an analyst picks it up.
What happens next is a predominantly human process.
The analyst reads the alert title and forms an initial hypothesis. They read the runbook, which walks through a set of investigation steps: check whether the asset is managed, look up the user’s recent authentication history, cross-reference against known-bad IPs, and verify whether this behavior has been seen before for this user or peer group. Each step requires navigating to a different tab or running a different query. The analyst mentally assembles the context from those data points, reaches a judgment (risky or benign), and either escalates or closes.
SOAR platforms were built to accelerate this by automating the deterministic parts. If the IP is in a threat intel feed, automatically enrich it. If the asset is unmanaged, automatically change the severity. But the reasoning step, the moment where someone had to look at the assembled evidence and decide what it meant, always stayed with the human.
The whole system is optimized around that constraint. Runbooks are written to guide human judgment. Severity labels are calibrated to manage human attention. Alert descriptions are written to help a person quickly orient themselves. Even tuning decisions are fundamentally about protecting analyst time, because every suppressed alert reclaims capacity in a finite human queue. The detection lifecycle, from rule authorship to triage to tuning, is a system designed to move signals through human cognition as efficiently as possible.
That’s not a criticism. Given the constraints, the design is reasonable. But it means almost every convention we have around what a “good detection” looks like was shaped by human cognitive limits rather than by what’s actually optimal for identifying threats.
What Changes When the Reader Is an Agent
When an AI agent handles tier 1 alert triage, the reader of your detection changes entirely, reshaping the requirements and design for a good detection.
The most important shift is that the detection’s metadata, which existed to orient a human investigator, now serves a fundamentally different purpose.
A human analyst reads a description and fills in context from experience. They read a runbook and apply judgment at every step. An agent doesn’t do either of those things gracefully. What it does well is reason over explicit context: a clear statement of what this behavior means, what makes an instance of it risky versus routine, and what investigative goals to pursue. The gap between the two models — implicit knowledge versus explicit context — is where most traditional detections will fall short for agents.
The evolution is that detections stop being purely logical and become a combination of rule-based logic and an investigative prompt. The descriptions become a statement of the threat model: what adversary behavior this rule is designed to surface, why it matters, and what legitimate activity looks like in comparison. The runbook becomes agent instructions: the risk criteria the agent should reason over and the investigative goals it should work toward.
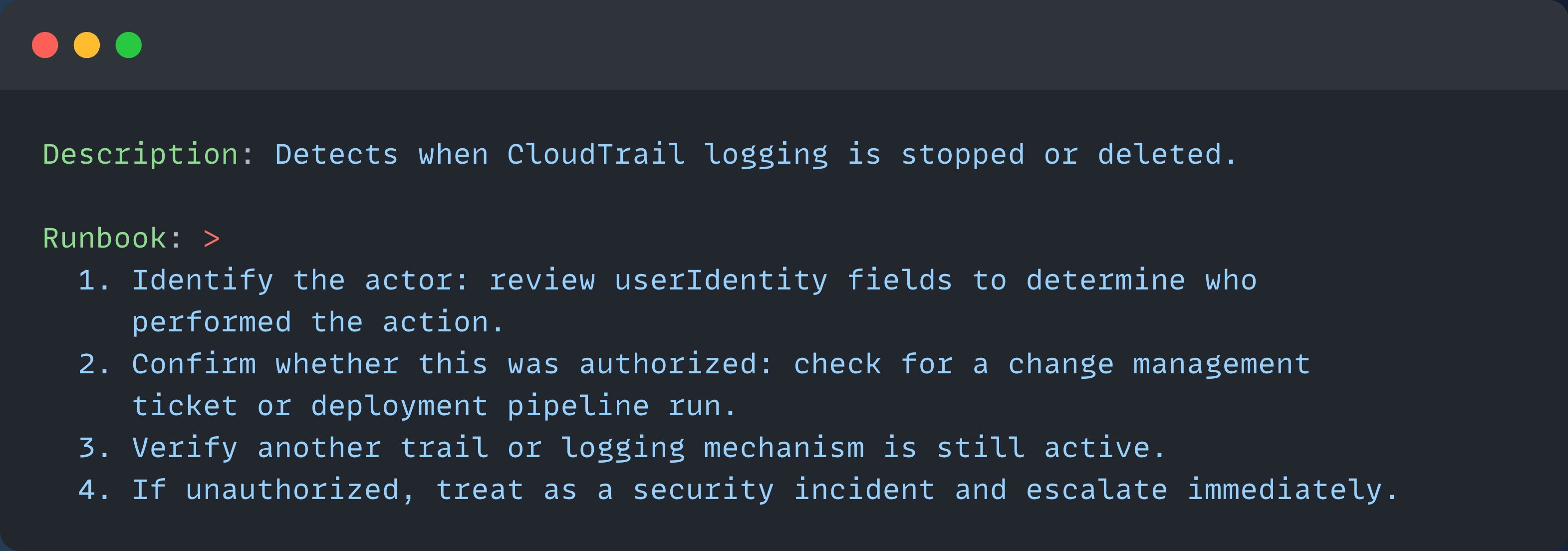
Here’s what that looks like in practice, using a real detection for CloudTrail StopLogging, a common technique for evading detection after gaining access to an AWS environment.
The traditional description and runbook are written for a human reader:
The AI-native version provides a threat model and decision framework rather than a procedure. While this description and runbook are longer, agents can write AI-optimized descriptions and runbooks tailored to your SOC’s operational practices, saving time across the entire lifecycle:
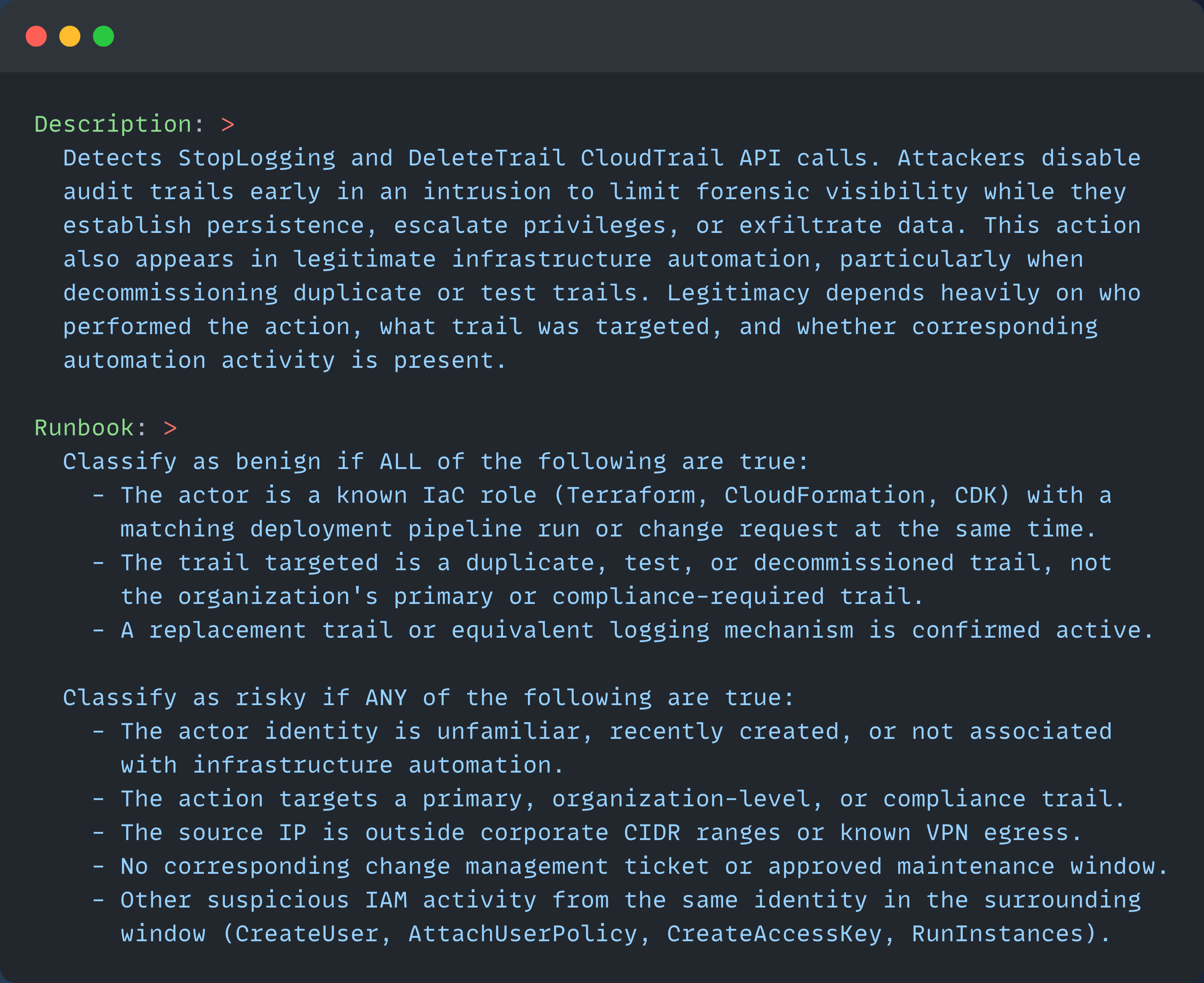
The detection logic is identical. What changed is how the agent is guided to work once the alert fires.
We actually ran this exact experiment. These two versions of this detection were deployed simultaneously on a live environment, both firing on the same event: a StopLogging call on a test trail using Stratus Red Team, performed via an admin from the same IP. Both agents ran the same SQL queries against the same CloudTrail data. The only variables were the runbook and description.
The difference in analysis came down to a single benign indicator that only the AI-native agent surfaced: the detection rule itself had been modified 10 minutes before the StopLogging action, and a detection update occurred at almost the same timestamp, a strong signal that this was active testing rather than an attacker disabling important audit trails.
That CI/CD signal appeared in both agents’ query results. The agent with the step-by-step runbook didn’t recognize it as relevant because its runbook said: “check for a change management ticket or deployment pipeline run.” The agent searched for a formal ticket but didn’t find one and moved on. The AI-native runbook’s explicit criterion — a known IaC role with a matching deployment pipeline run at the same time — primed the agent to scan for CI/CD activity, which is how it discovered the detection upload and weighted it as a meaningful, benign indicator.
The runbook didn’t change the agent’s investigation. It changed what the agent recognized as meaningful and how it ultimately scored the alert’s risk level.
Give Agents Goals, Not Scripts
The traditional runbook’s numbered steps are written for a human who reads “check for a deployment pipeline run” and intuitively knows to look at CI/CD history, recent commits, Slack messages, and deployment logs. An agent reading the same instruction performs a more literal interpretation: it looks for what the instruction most directly implies, finds nothing, and moves on. The AI-native runbook closes that gap by encoding the analyst’s implicit reasoning explicitly, as structured risk criteria rather than procedural steps.
Over-specifying investigation steps creates a different problem: it turns a reasoning system into a script executor. An agent told exactly what to do in a fixed sequence will do exactly that, even when the situation it encounters doesn’t fit the template. If the actor ARN immediately matches a known provisioning role at 2 pm, a scripted agent wastes steps. If unusual IP geolocation activity appears at 2 am, a scripted agent may not place much weight on it because it wasn’t in the procedure. Agents perform better when the runbook specifies what a correct conclusion looks like and leaves room for them to find it.
That said, specificity is right in some cases. Compliance-driven response procedures are one: if your controls require a specific notification within a defined time window when certain events occur, explicitly tell the agent. Response actions with real-world consequences are another, disabling an account, revoking credentials, and isolating a host. Those deserve prescribed guardrails because the cost of the agent improvising is too high. The principle isn’t “never be specific,” it’s that specificity should be reserved for the parts of the workflow where deviation genuinely creates risk. For investigation and reasoning, leave room.
Severity labels are worth addressing briefly here as well. For humans, severity was a prioritization tool (”high” meant “interrupt what you’re doing”). For agents, severity is an input to routing and escalation logic. That distinction changes how it should be assigned: less about managing analyst attention and more about accurately encoding the risk profile of the detected behavior so the agent routes correctly. A medium-severity detection that should almost always resolve as benign is different from a medium-severity detection that’s genuinely ambiguous. Encoding that distinction in severity, or in the description, gives the agent better inputs for its routing decision.
The Tuning Problem Inverted
One of the most counterintuitive aspects of the agentic SOC is what happens to the noise problem.
In the human-led model, alert fatigue was the central operational challenge. Teams spent enormous energy tuning detections to reduce noise rates because every alert was burning analyst time they couldn’t get back. The economics were simple: analyst hours are finite, and every wasted alert is a tax on a resource you can’t scale cheaply.
AI agents change those economics in one important way and leave them unchanged in another. Agents don’t get fatigued by volume. They can process alert queues at a scale no human team could match, so the raw-volume problem that drove so many tuning decisions largely goes away. You no longer need to suppress a class of alerts because your analysts can’t get to them.
But noise still matters.
Bad data (low-quality signals, alerts that fire on activity the agent has no meaningful way to distinguish from benign behavior, detections without sufficient context for the agent to reason about) creates two new problems.
First, it’s expensive. Every alert an agent processes consumes tokens, and every tool call it makes to investigate a low-signal alert, pulling enrichment, querying logs, assembling context, compounds that cost. At scale, a noisy detection program isn’t just a quality problem; it’s a budget problem.
Second, it pollutes reasoning. An agent that processes large volumes of low-signal alerts doesn’t burn out; it builds up a pattern of confident-but-wrong conclusions that is hard to audit and even harder to trust. Alert fatigue in the human model degraded analyst morale and response time. The agentic equivalent degrades decision quality in ways that are less visible and harder to catch.
The tuning imperative shifts from protecting analyst attention to protecting agent reasoning quality. The goal of tuning isn’t really to reduce alert volume in aggregate anymore; it’s to ensure that what fires is something the agent can make a meaningful decision about, either because the signal is clean enough to act on autonomously or because it’s genuinely ambiguous enough to warrant routing to a human.
In practice, this creates a new kind of tuning question: not just “is this alert noise?” but “does this alert give the agent what it needs to make a good call?” A detection that produces a technically accurate signal but lacks the enrichment and context for confident agent reasoning is effectively noisy in the agentic model, even if it would have been workable for a human analyst who could go gather that context manually. The threshold for what constitutes a well-formed detection gets higher.
Where Humans Still Own the Work
None of this means analysts are now obsolete. It means the nature of the work shifts, and understanding where that shift lands is important for teams thinking about how to structure their security operations going forward.
The work that remains deeply human is the strategic layer: deciding what to monitor in the first place. Threat modeling (mapping the specific assets, workflows, and data flows that matter for your organization and identifying the attack paths that could reach them) requires organizational context that agents don’t inherently have. Compliance requirements are similar: understanding which controls need to be verifiable, what your audit obligations are, and how to translate those into detection coverage requires judgment about business risk, not just pattern matching over log data. We’ve explored this in prior posts on threat modeling and detection coverage strategy, and the same principle applies here. Agents are very good at executing against a well-defined coverage map; they’re not yet good at defining what that map should look like in the first place.
Novel threat recognition is another area where humans hold an edge that matters. Agents reason well over patterns they’ve been given context for (known TTPs, behaviors encoded in detection logic, threat models that have been explicitly documented). What they struggle with is recognizing that something new and previously unmodeled is happening. Experienced analysts develop intuition for when a pattern doesn’t match anything they’ve seen before, which is a fundamentally different skill from applying existing knowledge. That intuition still needs to be in the loop.
Response decisions with real-world consequences belong here as well. When an investigation concludes that an account has been compromised, the question of whether to disable it, notify the user, involve legal, or escalate to executive leadership involves organizational, legal, and relationship considerations that agents aren’t equipped to navigate. Agents can surface findings and recommend actions, but the accountability for consequential decisions should stay with people.
And finally, humans need to maintain a critical eye on agent reasoning itself. Agents can be wrong in confident, systematic ways that are harder to catch than the more obvious mistakes a tired analyst might make. Someone needs to review the agents’ decisions, identify patterns in cases they’re getting wrong, and update the detection logic and context when agent reasoning consistently goes off track. Oversight of the agents becomes a core analyst function.
Building Toward This Transition
Teams that want to take advantage of what agentic triage makes possible need to carefully consider what must be true in their environment for it to work. The shift from human-led to agent-led triage isn’t just an architectural change; it requires rethinking the context that agents receive to properly delegate triage to the quality expected of senior team members.
The most important investment is in the data layer. Agents reason over what’s available at alert time. If your detections fire against raw, un-enriched log data with inconsistent field naming and no behavioral context attached, agents will make poor decisions regardless of how capable the underlying model is. Normalized schemas, enriched asset context (is this device managed? is this account a service account?), and behavioral baselines (is this unusual for this user or peer group?) should be present in the data that feeds the agent. This is one of the core reasons the security data lake architecture matters: it provides the queryable, structured foundation that enables agentic reasoning at scale.
The second investment is in detection quality as a prompt engineering problem. Start treating your detection descriptions and runbooks as context for a reasoning system, not instructions for a human reader. What does the agent need to know about why this behavior is suspicious? What context should it gather? What criteria distinguish risky from benign in this specific case? The detection engineering discipline doesn’t go away; it gets more rigorous because the output of that work now needs to be interpretable by an AI system, not just a person.
The third investment is organizational. The shift toward agentic triage creates room to reallocate analyst time toward detection coverage, threat modeling, and oversight, but that reallocation doesn’t happen automatically. Teams that get the most out of this transition will be deliberate about it, giving analysts explicit ownership of the strategic coverage questions while building the feedback loops that let agent performance improve over time.
The goal is a flywheel: better threat modeling yields better detections, which give agents better context, which in turn surfaces better signal, and that signal informs the next round of threat modeling. Getting that flywheel moving is the real work of building an agentic SOC and closing the loop.
The experiment described above was run live on a real Panther deployment, using Panther both as the detection system and as the agentic triage engine evaluating the alerts. If you’re building toward the agentic SOC vision described here, that’s exactly what we’ve built with Panther. Reach out or reply to this email, and I’ll give you a demo.
Recent Posts


Cover photo by Ed Robertson on Unsplash