

How AI Agent Tools Work: A Practical Guide for SOC Analysts
How tool calling turns natural language questions into actionable security investigations.

Welcome to Detection at Scale, providing weekly insights on building AI-powered security operations, from detection-as-code to autonomous triage for practitioners managing threats at cloud scale. Subscribe now to stay up-to-date!
Today, you write SIEM queries. Tomorrow, you’ll supervise an agent who writes them for you. AI agents represent the ultimate evolution of security automation, building dynamic, nondeterministic investigation paths that traditional playbooks can’t anticipate.
Consider triaging a phishing email alert. You identify the delivery method, determine who received it, validate if anyone clicked the link, hunt for signs of credential theft, and track lateral movement if credentials were compromised. The typical response flow involves multiple manual queries across various systems, but with agents, this transitions to typing a series of coherent, natural-language questions. But how does the agent know where to look? How does it understand the query syntax for accessing the data to answer the question? How does it access your threat intelligence feeds or ticketing systems for context? The answer is tool calling.
Tools are structured interfaces that serve as the middleware layer between an agent’s reasoning and the execution of tasks in your various security platforms. A tool might be as simple as search_alerts with a clear function that accepts time ranges and filter conditions, or as sophisticated as indicator_pivot that chains multiple queries across systems before returning an answer. The agent uses these tool definitions to properly format queries, make correct API calls, and access the appropriate data sources.
The result is a powerful virtual assistant that can perform everyday security analysis tasks that require interaction with data and tools, quickly triaging alerts, confirming hypotheses, and synthesizing answers across large, complex data sets.
In this post, we’ll examine how tools define agent capabilities, how they decide which tools are most appropriate to call based on the situation, and the constraints you should know while using agents. These concepts will help you become more effective and productive by delegating work to AI agents.
Quick note: I’m the Founder/CTO at Panther — a SOC platform helping security teams scale with AI agents and as-code workflows. In this post, I’ll use examples of how Panther powers these agent workflows in leading SOCs. If you want to see the product behind the ideas, you can check it out here.
How Tools Define What Your Agent Can Actually Do
We all have experience using AI to summarize text, spot patterns, or answer questions, thereby expediting analysis. But for agents to carry out the work delegated to them, they need tools to access real-world context or to perform tasks dynamically. Remember, LLMs (Large Language Models) are bound by their training data, and tools serve as a bridge to break free from that isolated knowledge. By providing agents the same access to security tooling as human security analysts, they can execute similar work in the SOC and become a force multiplier on our teams. But what do tools look like in practice? How are they defined? Let’s explain using an everyday use case: Alert Tuning.
Every day, security teams triage and resolve alerts that flag high-risk behaviors. As teams process these alerts, they interpret what happened, gather surrounding context, and make a judgment call. When alerts are noise, the analyst determines which part of the rule failed and documents the findings in a ticketing system like Jira to prevent future alerts.
What would it look like to automate that process with an AI agent? It would need access to read the detection logic, review the created alerts, query log data, and then file a ticket. Let’s see this in action with Panther’s AI copilot:

Let’s dissect what’s happening here. The user asks a question about tuning CloudTrail alerts from the last three weeks. The agent calls a tool to list alerts for that timeframe, discovers 18 alerts, then fetches each detection rule to understand why those alerts originated. Once it has this external context, it reasons about which rules need tuning and which are working correctly, and produces an analysis for how fewer or more accurate alerts could have been generated.

This agent revealed that most rules appear to be legitimate administrative actions, which is a great observation and creates solid candidates for tuning. One particular piece of feedback was identifying a redundant rule that caused duplicate alerts and increased work for the team:
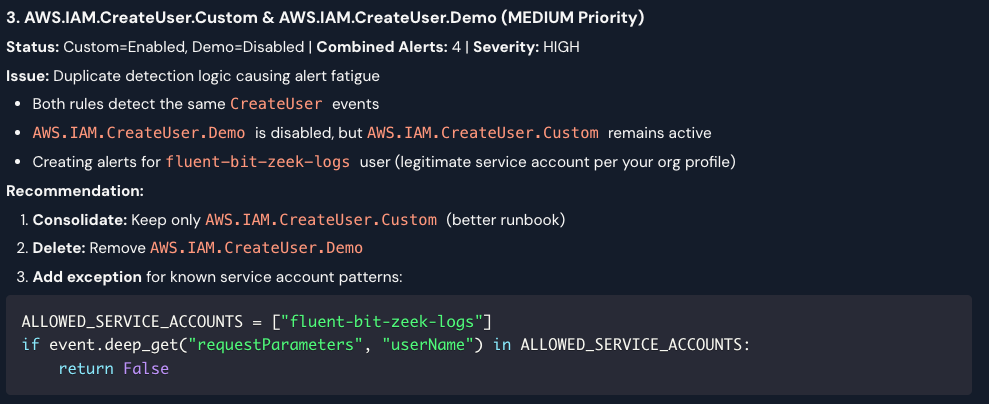
Tool Definitions
Tools accomplish a specific task and contain a description that explains when they should be used and the expected output. This combination of tools, each with clear boundaries and purposes, combines into an agent that performs a specific role on your security team. Tools are defined using a name, description, and a set of parameters:
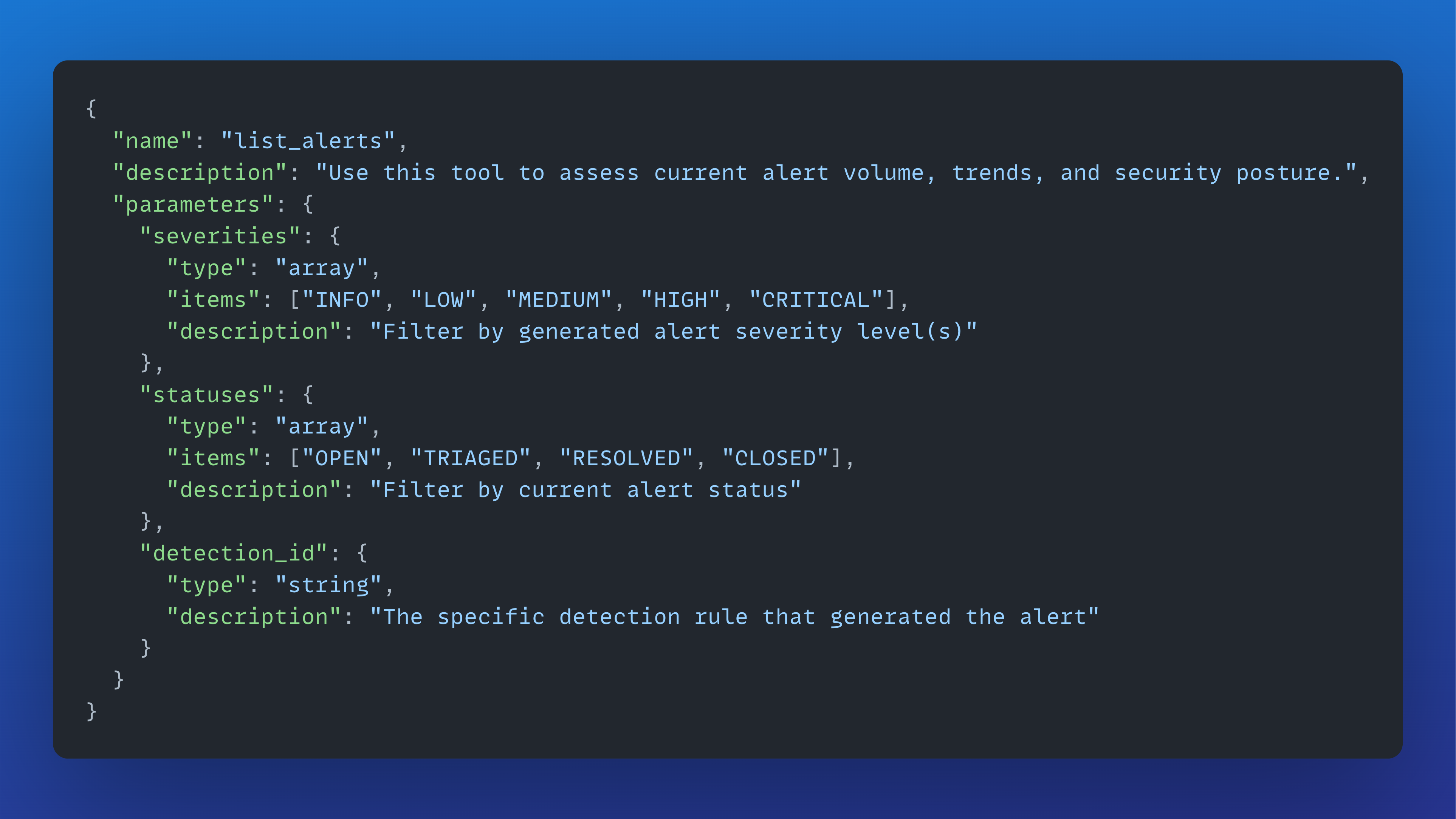
These tools are then loaded into the agent’s system prompt, and once an agent decides to use a tool, it passes parameters to obtain the correct output. For example, when an analyst asks, “Show me all high alerts from yesterday,” the agent parses that request, recognizes that list_alerts is the appropriate tool, and constructs a function call with severities=[”HIGH”] and appropriate date parameters.
Understanding how agents decide which tools to use can help ensure they carry out delegated tasks correctly. Let’s learn how to influence their decisions in the right ways.
How Agents Decide Which Tools to Use (And How to Guide Them)
There are two ways agents choose which tools to use, and understanding the distinction changes how you approach your role in the process.
The first is direct invocation, where you use the agent as an execution layer. You say, “list alerts from failed logins in the last hour,” and the agent dutifully calls the list_alerts tool with those exact parameters. You’re the director; the agent is just translating your natural language into the proper tool call.
The second is agentic invocation, where you give the agent a higher-level goal and it decides which tools to use and in what sequence, based on its reasoning about the information it needs. You say, “We need to investigate the privilege escalation alert and find any related signs of compromise.” The agent uses its available tools to check the alert details, look up the user’s recent activity, compare that activity pattern against historical baselines, and check threat intelligence for the source IP. You’ve shifted from investigator to supervisor.
The way agents select tools depends on the clarity of tool declarations, the task you’ve given them, and any constraints in your instructions. When an agent receives a task, it examines all available tools, reads their descriptions to understand what each does, and builds a mental model of how it might accomplish the goal. It follows similar reasoning you would use as an analyst. The difference is that you’ve learned investigation patterns through experience and training, while the agent learns them through the quality of your prompts and examples.
The most effective way to teach agents good tool orchestration is to show them what good investigations look like. This is called few-shot prompting, and in the context of cybersecurity agents, it’s documenting and relaying to the agent how you’d handle a case. Take a phishing investigation: “When investigating phishing, first check the sender and recipients, then find logs for anyone that clicked embedded links, and create an alert to detect any follow-on activity.” By giving the agent these example workflows, you’re teaching it the investigative rhythm and logic that should carry over to similar cases.
Now that we have covered how tool selection occurs, let’s dive into the limitations and constraints of tool use and the optimal methods for keeping agents focused.
Tool Constraints: Keeping Agents Focused and Effective
When you’re investigating an alert, you don’t start by pulling every log from every system for the past month. You scope deliberately. You ask targeted questions, you narrow your searches to relevant timeframes and systems, and you gather just enough context to reach a conclusion. When you’re dealing with security logs that can scale into terabytes across dozens of sources, this discipline is essential. The same principle applies to agents, but unlike human analysts who develop intuition about reasonable scope through experience, agents need explicit guidance about how to investigate efficiently.
Here’s what happens when agent investigations lack proper constraints. An analyst asks, “Was this authentication successful?” and the agent, seeing that it has access to a broad set of tools, decides to pull all authentication events for that user across all systems for the past week, then all network activity for those same systems, then all process execution logs from any endpoint that user touched. The agent isn’t being malicious or careless; it’s trying to be thorough. But now you’re waiting five minutes for results that should have taken 30 seconds, you’re spending tokens processing megabytes of irrelevant log data, and the agent’s working memory is cluttered with extraneous information that obscures the actual answer.
The underlying issue is that each tool call adds conversational turns to the agent’s reasoning process, and more turns create more opportunities for attention drift and degraded reasoning quality. An agent that makes 15 tool calls to answer a simple question isn’t just slow and expensive; it’s more likely to lose track of the original question or weigh irrelevant information too heavily in its final answer. The goal isn’t to prevent agents from using multiple tools when necessary; it’s to ensure each tool call is purposeful and moves the investigation forward rather than sideways.
The fix is understanding that agent focus comes from two sources: well-designed tool definitions and clear guidance in your prompts. If you’re building tools yourself, make them specific to investigation patterns rather than generic data access. Instead of a single broad search_logs tool, create focused tools like check_authentication_outcome that accepts a user, timestamp, and source system, and returns only the success or failure status. Tools with clear, narrow purposes naturally guide agents toward efficient investigations because agents don’t have to make complex decisions about how to scope their queries.
The other lever you control is the instructions and examples you provide. Be explicit about investigation scope: “Check only the past hour unless you find a suspicious pattern,” or “Start with authentication logs, only expand to network logs if you see evidence of lateral movement.” This is where AI playbooks become essential, representing the evolution from manual step-by-step procedures to encoded instructions that agents follow autonomously. Traditional playbooks told humans which buttons to click and which queries to run. AI playbooks encode the reasoning behind those decisions so agents can adapt the investigation to what they find.
For impossible travel alerts, an AI playbook might specify: “Compare authentication locations and timing. If locations are more than ~500 miles apart and there is less than 1 hour between them, check for concurrent sessions. Only query network logs if you find evidence of account takeover.” You’re teaching the agent the same investigation discipline you’d teach a junior analyst, but you have to be more explicit because the agent can’t read between the lines or apply common sense about what “reasonable scope” means. When agents have clear guidance about how to use tools efficiently, you get faster investigations, lower costs, and more reliable conclusions because the agent isn’t drowning in its own data collection.
From Writing Queries to Harnessing AI Capabilities
The shift from performing investigations manually to supervising agents is about the analyst’s job evolving to a higher level of leverage.
Understanding tools changes what it means to be effective in an AI-first SOC, because you’re no longer executing investigations end-to-end; you’re designing the guidance agents use. When you write an AI playbook that encodes how to investigate impossible travel alerts, you’re creating reusable investigative logic that handles hundreds of similar cases without your direct involvement. This is the fundamental skill that separates analysts who thrive with AI agents from those who struggle with them.
Start by picking one investigation workflow you handle repeatedly, document it as if you’re training a junior analyst, and encode it as guidance for your agent. Be explicit about which tools to use, when to expand scope, and what findings should trigger deeper investigation. Test it, refine it based on how the agent actually performs, and you’ll quickly develop intuition for what makes agents effective versus what leads them astray. The analysts who master this are learning to teach agents how to investigate effectively rather than just investigating themselves. That’s the skill that matters going forward, and it starts with understanding that tools are the interface between what agents can reason about and what they can actually do in your environment.
Thank you for reading! To get more blogs like this, subscribe below.
If you are implementing the AI SOC workflows mentioned in this post but don’t want to build it from scratch, check out Panther! We provide a highly scalable SIEM with AI agents for autonomous triage, threat hunting, and natural language search. Security teams using Panther triage 80% of their alerts autonomously while keeping analysts focused on complex cases that require human judgment. Reach out to discuss bringing AI agents into your security operations. You can also send me a DM below. Thanks!